สวัสดีครับวันนี้จะมาแชร์เรื่อง
Simple Linear Regression โดยการนำ
Machine learning มาคำนวณเพื่อให้เห็นภาพและเข้าใจได้ง่ายถึงหลักการทำงานของ
ML ที่เป็นรูปแบบของ
Supervised Learning ครับ (Supervised
Leaning คือการให้โปรแกรมเรียนรู้จากข้อมูลที่รู้ผลแน่ชัดอยู่แล้ว
ถ้าให้เปรียบเทียบกับคนก็เหมือนกับให้โปรแกรมอ่านหนังสือก่อนที่จะนำเอาความรู้จากหนังสือที่ได้ไปประยุกต์ใช้งานนั้นเองครับ หรือหากอยากศึกษาเพิ่มเติมสามารถศึกษาได้ที่
นี่
ครับ)
“แล้ว Simple Linear Regression คืออะไร”
Linear Regression คือ การหาสมการเชิงเส้นเพื่ออธิบายข้อมูล ยกตัวอย่างเช่น เรามีข้อมูลราคาการเช่าหอแต่ละเดือนในกรุงเทพเมื่อเทียบกับพื้นที่ห้องดังนี้
พื้นที่ (m2)
|
ค่าเช่าหอต่อเดือน (บาท)
|
22.5
|
2100
|
24
|
2800
|
26
|
3250
|
26.5
|
3600
|
30
|
3800
|
32
|
4300
|
34.5
|
4600
|
36.5
|
5000
|
38
|
5800
|
42
|
7000
|
หากเรานำข้อมูลมาวาดเป็นกราฟจะได้ข้อมูลดังนี้ครับ

แล้วถ้าเราอยากจะรู้ว่าถ้าหอในกรุงเทพที่มีขนาดห้อง 40 ตารางเมตรจะมีราคาประมาณเท่าไร เราสามารถคาดคะเนได้โดยการเอาเส้นแนวโน้มมาวาดบนกราฟดังนี้ครับ
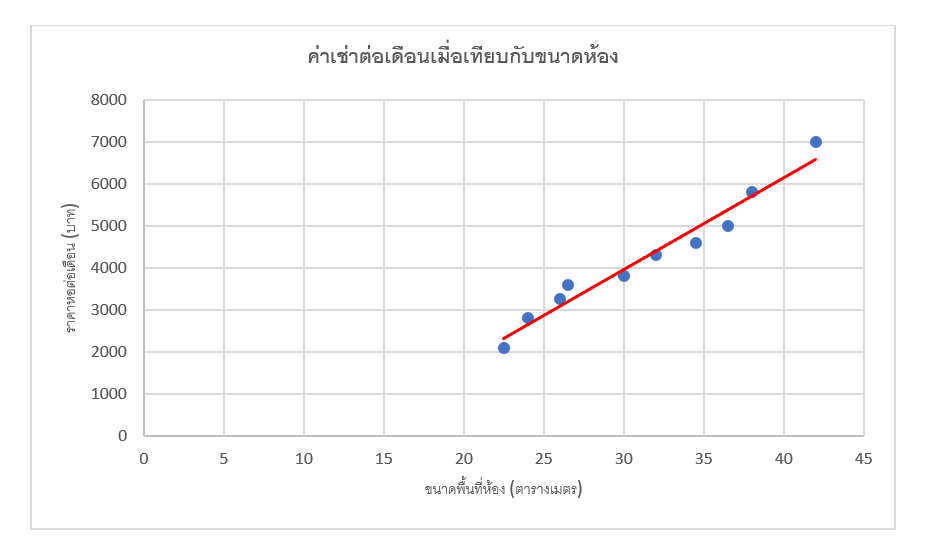
หลังจากเราวาดเส้นลงเราก็สามารถคาดคะเนได้ว่าถ้ามีขนาดห้อง 40 ตารางเมตร จะมีราคาประมาณ 6000 กว่าบาท

จะเห็นว่าที่เราวาดเส้นแนวโน้มของข้อมูลนั้นเราจะเรียกว่าเป็น Simple Linear Regression
“แล้วเราจะนำ Machine learning มาใช้งานร่วมกับ Simple Linear Regression อย่างไร”
เราจะเอา Machine learning มาใช้ร่วมกับ Simple
Linear Regression โดยให้ Machine learning มาทำการหาเส้นแนวโน้มในกราฟดังกล่าว แล้วนำไปใช้งานดังนี้

จากรูปด้านบนจะมีลำดับการนำไปใช้งานคือ
นำข้อมูลที่ต้องการประมวลผล
(feature) มาเข้า Model
แล้วทำนายออกมาว่าผล (Label) ที่ได้เป็นอย่างไร
ถ้าให้เปรียบเทียบการนำ
ML ไปใช้ กับการคาดคะเนราคาห้องเช่าจะเป็นดังนี้
- Feature คือข้อมูลที่ต้องการไปประมวลผล ในที่นี้จะหมายถึง ขนาดห้อง
- Model คือสมการหนึ่งที่สามารถใช้ในการคาดคะเนว่าผลที่ได้จะเป็นอย่างไร ในที่นี้จะหมายถึง เส้นแนวโน้ม หรือสมการเส้นตรงของเส้นแนวโน้มนั่นเอง
- Label คือผลที่ต้องการทำนาย ในที่นี้จะหมายถึงราคาห้อง
ซึ่งในการหา Model นั้นเราจะใช้ Machine Learning มาหาครับโดยมีหลักการทำงานที่จะได้ Model มาเป็นดังนี้

- จากรูปหลักการทำงานด้านบนเราจะนำข้อมูลที่เรามีอยู่แล้ว(Feature)และรู้ผลัพธ์อยู่แล้ว(Label)ให้ Machine learning ทำการเรียนรู้
- โดยในการเรียนรู้นั้นตอนแรก ML จะสร้าง Model ขึ้นมาก่อนซึ่ง Model ดังกล่าวยังไม่สามารถทำนายข้อมูลได้ถูกต้อง
- จึงต้องเข้าสู่กระบวนการ Train ข้อมูลเพื่อทำการปรับ Model ให้ถูกต้องมากที่สุดโดยกระบวนการ Train จะทำงานโดยการนำ Model มาทำนายผลจากข้อมูล(Feature)
- ซึ่งก็จะมีทั้งการทำนายที่คลาดเคลื่อนกับความเป็นจริงไปมาก หรือใกล้ความเป็นจริง (ในการดูข้อมูลว่าผลทำนายที่ได้คลาดเคลื่อนไปมากหรือใกล้ความเป็นจริงเราใช้ Cost Function ในการดู)
- ก็นำเอาค่าความเคลื่อนที่ได้ ไปปรับ Model เข้าหาผลลัพธ์ที่ถูกต้อง
- หลังจากนั้นจะทำการ Train ไปเรื่อยๆและปรับค่า Model ไปเรื่อยๆ
- จนใกล้เคียงข้อมูลจริงมากที่สุด
เพื่อให้เข้าใจได้มากขึ้นหากลองการทำงานของ ML มาใช้ในการหากราฟแนวโน้มเชิงเส้นสำหรับเปรียบเทียบข้อมูลราคาเช่าห้องกับขนาดห้องสามารถทำได้ดังนี้ครับ
- นำข้อมูลที่เรามีอยู่แล้ว(Feature ในที่นี้ของเราคือขนาดห้อง)และรู้ผลัพธ์อยู่แล้ว(Label ในที่นี้ของเราคือ ราคาห้อง)ให้ Machine learning ทำการเรียนรู้ ซึ่งจะได้เป็นกราฟด้านล่าง

- โดยในการเรียนรู้นั้นตอนแรก ML จะสร้าง Model(ในที่นี้คือเส้นแนวโน้ม) ขึ้นมาก่อนซึ่ง Model ดังกล่าวยังไม่สามารถทำนายข้อมูลได้ถูกต้อง (ในที่นี้คือเส้นแนวโน้มที่ได้ไม่สอกคล้องกับข้อมูล) ซึ่งอาจจะได้เป็นกราฟด้านล่าง
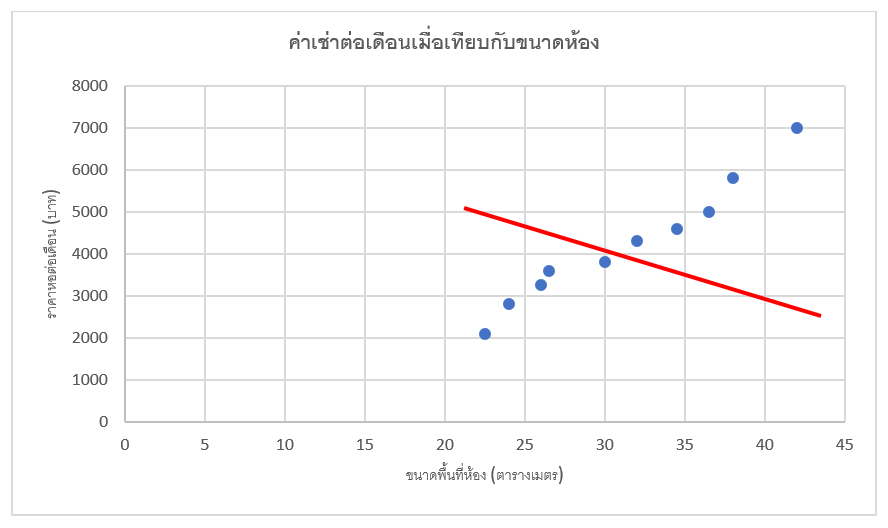
- จึงต้องเข้าสู่กระบวนการ Train ข้อมูลเพื่อทำการปรับ Model (ในที่นี้คือเส้นแนวโน้ม) ให้ถูกต้องมากที่สุดโดยกระบวนการ Train จะทำงานโดยการนำ Model มาทำนายผลจากข้อมูล(Feature)(จากรูปด้านล่างจะเห็นว่าเราต้องการทำนายราคาห้องที่มีพื้นที่ขนาด 43 ตารางเมตร ผลที่ได้ปรากฎว่า Model ทำนายราคาได้ประมาณเกือบ 3000 บาท)

- ซึ่งก็จะมีทั้งการทำนายที่คลาดเคลื่อนกับความเป็นจริงไปมาก หรือใกล้ความเป็นจริง (ในการดูข้อมูลว่าผลทำนายที่ได้คลาดเคลื่อนไปมากหรือใกล้ความเป็นจริงเราใช้ Cost Function ในการดู)(จากรูปด้านล่างจะเห็นว่าเราต้องการทำนายราคาห้องที่มีพื้นที่ขนาด 43 ตารางเมตร ผลที่ได้ปรากฎว่า Model ทำนายราคาได้ประมาณเกือบ 3000 บาทแต่ราคาจริงอยู่ที่ 7000 บาทซึ่งมีความคลาดเคลื่อนกับความเป็นจริงมาก)

- ก็นำเอาค่าความเคลื่อนที่ได้ ไปปรับ Model เข้าหาผลลัพธ์ที่ถูกต้อง

- หลังจากนั้นจะทำการ Train ไปเรื่อยๆและปรับค่า Model ไปเรื่อยๆ

- จนใกล้เคียงข้อมูลจริงมากที่สุด

สุดท้ายนี้หวังว่าโพสน์นี้จะมีประโยชน์สำหรับแนวทางในการเริ่มต้นศึกษา
Machine
learning ครับ
References
Linear Regression: https://ilog.ai/linear-regression-for-ml/