สมมุติเรามีข้อมูลของราคาการเช่าหอแต่ละเดือนในกรุงเทพเมื่อเปรียบเทียบกับพื้นที่ห้องดังนี้
พื้นที่ (m2)
|
ค่าเช่าหอต่อเดือน (บาท)
|
22.5
|
2100
|
24
|
2800
|
26
|
3250
|
26.5
|
3600
|
30
|
3800
|
32
|
4300
|
34.5
|
4600
|
36.5
|
5000
|
38
|
5800
|
42
|
7000
|
ซึ่งเราต้องการนำข้อมูลที่ได้ไปวาดกราฟ ดังนี้ครับ

สิ่งที่เราต้องการนำ
ML มาช่วยคือการหา
Model ซึ่งในรูปแบบของ
Simple Linear regression นั้นก็คือ
เส้นแนวโน้มดังนี้ครับ

ดังนั้น Model ในที่นี้จะเป็นการหาเส้นแนวโน้มจากเส้นสีแดงข้างบน
เพื่อไว้ใช้สำหรับทำนาย (Predict) ข้อมูล ตัวอย่างเช่น เราต้องการอยากรู้ว่าถ้าขนาดห้อง 40 ตารางเมตร เราสามารถนำ Model ที่หาได้ มาทำนาย (Predict) ดังนี้ครับ

จากรูปด้านบนจะเห็นว่าที่พื้นที่ห้องขนาด 40 ตารางเมตรจะมีราคาหอต่อเดือนประมาณ 6000 กว่าบาทเมื่อเปรียบเทียบกับ
Model
(ในที่นี้คือเส้นแนวโน้มสีแดง)
“แล้วจะให้คอมพิวเตอร์เข้าใจ
Model (ในที่นี้คือเส้นแนวโน้ม) อย่างไร?”
Model ในทางคอมพิวเตอร์เป็นสมการหนึ่ง
สมการ Model ใน Simple linear Regression
นั้นก็คือเส้นแนวโน้มที่เป็นเส้นตรง
ซึ่งเราสามารถสร้างเป็นสมการเส้นตรงได้ดังนี้ครับ
y = mx+b
และถ้าดูจากเส้นแนวโน้มดังรูปเราสามารถสร้างเป็นสมการเส้นตรงได้ป็น
y= 219x-2607.7
หมายความว่าค่า m =
219 , b = -2607.7

หลังจากเราได้ Model เป็นสมการ
y= 219x-2607.7
เราสามารถนำ Model มาทำนายได้แล้วครับ
สมมุติเราต้องการหาราคาหอเมื่อมีขนาดพื้นที่
40 ตารางเมตร
เราสามารถหาได้โดยการนำไปเข้าสมการดังนี้ครับ
y = 219(40)-2607.7 =
6152.3
จะเห็นว่าจะได้ราคาประมาณ 6000 กว่าบาทหรือนั่นก็คือ 6152.3 บาท
“แล้วเราจะหาค่า m และ b ในสมการ
y=mx+b อย่างไร?”
ในการหา m และ b นั้นเราจะใช้ Machine
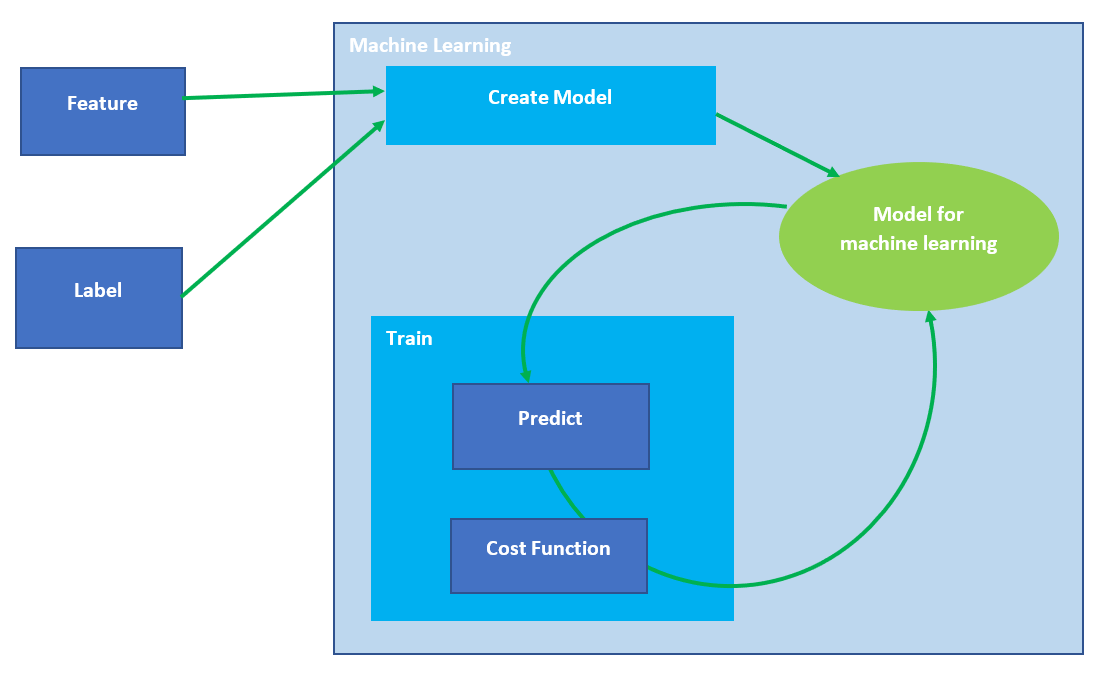
learning ในการหาโดยมีขั้นตอนการทำงานดังรูป
·
จากรูปหลักการทำงานด้านบนเราจะนำข้อมูลที่เรามีอยู่แล้ว(Feature)และรู้ผลลัพธ์อยู่แล้ว(Label)ให้ Machine learning ทำการเรียนรู้
·
โดยในการเรียนรู้นั้นตอนแรก ML จะสร้าง Model ขึ้นมาก่อนซึ่ง Model ดังกล่าวยังไม่สามารถทำนายข้อมูลได้ถูกต้อง
·
จึงต้องเข้าสู่กระบวนการ Train ข้อมูลเพื่อทำการปรับ Model ให้ถูกต้องมากที่สุดโดยกระบวนการ Train จะทำงานโดยการนำ Model มาทำนายผลจากข้อมูล(Feature)
·
ซึ่งก็จะมีทั้งการทำนายที่คลาดเคลื่อนกับความเป็นจริงไปมาก
หรือใกล้ความเป็นจริง (ในการดูข้อมูลว่าผลทำนายที่ได้คลาดเคลื่อนไปมากหรือใกล้ความเป็นจริงเราใช้ Cost Function ในการดู)
·
ก็นำเอาค่าความเคลื่อนที่ได้ ไปปรับ Model เข้าหาผลลัพธ์ที่ถูกต้อง
·
หลังจากนั้นจะทำการ Train ไปเรื่อยๆและปรับค่า Model ไปเรื่อยๆ
จนใกล้เคียงข้อมูลจริงมากที่สุด
“Cost Function คืออะไร?”
จากขั้นตอนการทำงานของ Machine
learning จะเห็นว่าจะมีการเข้า Cost Function
แล้ว Cost Function คืออะไร
Cost Function คือ สมการในการหาค่าความ
Error ของ Model ที่ใช้ในการทำนาย(Predict)
ซึ่งค่า Cost Function ยิ่งมีค่ามากแสดงว่า Model
ที่ใช้ในการทำนาย(Predict) ยิ่งมีความ Error
มาก
ในสมการ Cost Function จะมีหลากหลายสมการที่ใช้ในการคำนวณหาค่า
Error ซึ่งในที่นี้เราจะใช้สมการที่เรียกว่า Mean Squared Error (MSE) โดยมีสมการดังนี้
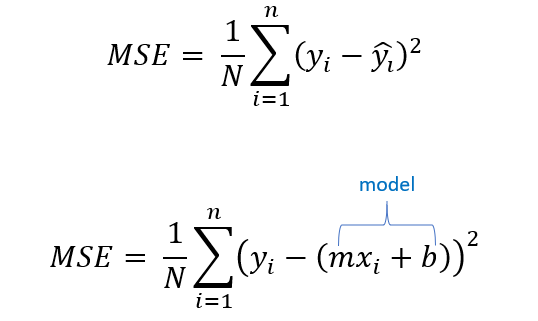
หรือมองเป็นรูปภาพได้ดังนี้ครับ

“แล้วเราจะไปปรับค่า
Model อย่างไร?”
เนื่องจาก Model เราคือสมการเส้นตรง y=mx+b
ดังนั้นเราสามารถปรับค่า m และ b เพื่อให้ได้ค่า Cost Function ที่น้อยที่สุดที่เป็นไปได้
“แล้วเราจะรู้ได้อย่างไรว่าควรปรับค่า m เท่าไหร่ ปรับค่า b เท่าไหร่”
ในการปรับค่า m ค่า b เราจะพิจราณาจาก
Gradient Descent Derivation ในการปรับค่า m และ ค่า b โดยหลักการ Gradient Descent เป็นดังนี้ครับ
Gradient Descent คือ การหา Slop ที่ไล่ลงมารื่อยๆ จากรูปด้านล่างดังนึ้ครับ

จากรูปจะเห็นว่าเป็น
รูประฆังหงาย ที่เกิดจากการนำเอาค่า Cost Function ที่เราปรับ Model มาหลายๆครั้งมาคำนวณค่า
Cost Function แล้วเอามา Plot จะเกิดเป็นรูประฆังหงายดังรูป
โดยค่าที่อยู่ก้นระฆังนั้นจะหมายความว่าค่า Cost Function มีค่าเท่ากับ
0 หรือหมายความว่า model ที่ใช้ในการคำนวณนั้นมีความคลาดเคลื่อนจากข้อมูลจริงเป็น
0 หรือมีความแม่นยำมากๆในการทำนาย ดังนั้นจึงสรุปได้ว่า ถ้าค่า
Cost function ยิ่งอยู่บริเวณก้นระฆังมากเท่าไหร่แสดงว่า Model
นั้นย่อมมีความแม่นยำมาก
“แล้วเราจะรู้ได้อย่างไรว่าจะปรับค่า
m และ b ในสมการ y=mx+b เท่า
ไหร่บ้าง”
เราจะดูค่า แนวโน้มว่า m และ b ควรปรับเพิ่มขึ้นหรือปรับลดลงโดยดูจากความชันของจุดข้อมูลที่เราทำการ
Train แต่ละครั้ง
“แล้วเราจะดูความชันอย่างไร”
เราจะใช้คณิตศาสตร์ Calculus ในเรื่องของการหาอนุพันธ์(derivative) นั่นเอง โดยการหาอนุพันธ์ (derivative) ของฟังก์ชันใดๆ จะได้สมการความชันของฟังก์ชันนั้นๆ
ยกตัวอย่างการหาอนุพันธ์
สมมุติเรามีสมการ

หรืออาจจะเขียนใหม่ได้ว่า

ซึ่งสามารถนำสมการมาวาดกราฟได้ดังนี้

ทำการอนุพันธ์สมการ
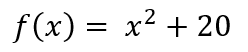
จะได้

จะเห็นว่าสมการ

จะเป็นสมการที่บอกความชัน
ณ จุดใดๆ ของสมการ

เช่นเราต้องการรู้ความชัน
ที่ x = -5 เราก็เอาค่า x ไปแทนในสมการ
ซึ่งค่าความชันที่ได้เป็น -10 ดังรูป

หรือหากเราต้องการจะรู้ความชันที่
x=5 เราเอาค่า x ไปแทนในสมการ
ค่าความชันที่ได้เป็น 10 ดังรูป

จากตัวอย่างจะเห็นว่า
การหาอนุพันธ์ จะได้สมการที่บอกความชันของแต่ละจุดซึ่งความชันที่ได้จะมีค่า
เป็นจำนวนเต็มบวก หรือจำนวนเต็มลบ
โดย
ค่าเป็นจำนวนเต็มลบ จะหมายถึงกราฟมีความลาดชันลง
ค่าเป็นจำนวนเต็มบวก จะหมายถึงกราฟมีความลาดชันขึ้น
ซึ่งหากเรารู้ว่าค่าความชันเป็นจำนวนเต็มบวก
เราก็ต้องลดค่า x ลง
เพื่อให้เข้าใกล้ก้นรูประฆัง
แต่หากเรารู้ว่าค่าความชันเป็นจำนวนเต็มลบ
เราก็ต้องเพิ่มค่า x ขึ้น
เพื่อให้เข้าใกล้ก้นรูประฆังเช่นกัน
เราจึงเอาความชันนี่แหละมาประยุกใช้ในการปรับ
Model
“การเอามาประยุกต์ใช้”
จากที่เรารู้ว่าสมการในการตรวจสอบความคลาดเคลื่อนของ
Model ที่เรียกว่า Cost
Function ซึ่งเราใช้สมการที่เรียกว่า Mean Squared Error (MSE) ที่มีหน้าตาสมการดังนี้

เราก็เอาสมการดังกล่าวมาเข้าอนุพันธ์ก็จะได้

เราก็จะได้สมการที่ใช้ในการบอกความชันแล้วครับ
หลังจากเราได้สมการความชันของ
Cost Function แล้วเราก็จะเอาสมการดังกล่าวมาใช้ในการปรับค่า
m และ b ครับ
เพื่อให้เข้าใจในการทำงานมากขึ้นจะมีการทำงานของ
Machine learning ดังนี้
- ข้อมูลที่เรามีอยู่แล้ว(Feature)และรู้ผลลัพธ์อยู่แล้ว(Label)ให้ Machine learning ทำการเรียนรู้
Feature ในที่นี้พื้นที่ (m2)
|
Label ในที่นี้คือค่าเช่าหอต่อเดือน (บาท)
|
22.5
|
2100
|
24
|
2800
|
26
|
3250
|
26.5
|
3600
|
30
|
3800
|
32
|
4300
|
34.5
|
4600
|
36.5
|
5000
|
38
|
5800
|
42
|
7000
|
- โดยในการเรียนรู้นั้นตอนแรก ML จะสร้าง Model ขึ้นมาก่อนซึ่ง Model ดังกล่าวยังไม่สามารถทำนายข้อมูลได้ถูกต้อง
- Model ในที่นี้คือ สมการเส้นตรง y=mx+b (y คือ ราคาของห้อง, x คือ พื้นที่ของห้อง)
- ในการสร้าง Model โดยการสุมค่า m และ b ขึ้นมา สมุติสุ่มค่า m ได้ 210 สุ่มค่า b ได้ -2600 (m=210, b=-2600)
- ซึ่ง Model ที่เกิดจากการสุ่มค่า m และ b นั้นยังไม่สามารถทำนายข้อมูลได้ถูกต้อง

- จึงต้องเข้าสู่กระบวนการ Train ข้อมูลเพื่อทำการปรับ Model ให้ถูกต้องมากที่สุดโดยกระบวนการ Train จะทำงานโดยการนำ Model มาทำนายผลจากข้อมูล(Feature)
- จาก model ที่เรามีคือ y=210x-2600 (y คือ ราคาของห้อง, x คือ พื้นที่ของห้อง)
- ทำนายราคาห้อง(y) เมื่อมีขนาดพื้นที่ห้องเป็น 22.5 ตารางเมตร (x=22.5) ดังนั้น y = 210(22.5)-2600 = 2125

- ซึ่งก็จะมีทั้งการทำนายที่คลาดเคลื่อนกับความเป็นจริงไปมาก หรือใกล้ความเป็นจริง (ในการดูข้อมูลว่าผลทำนายที่ได้ คลาดเคลื่อนไปมากหรือใกล้ความเป็นจริงเราใช้ Cost Function ในการดู)
- เราจะใช้ Cost Function ในการตรวจสอบความคลาด จากสมการ Cost Function ซึ่งเราจะใช้สมการที่ชื่อว่า Mean Squared Error (MSE) ในการทำ Cost function ดังนี้

- เราเอาค่า m และ b มาแทนในสมการ

- เราก็เอาข้อมูล Feature ที่เรามีทั้งหมดมาทำนายก็จะได้ดังนี้ครับ

- จะเห็นว่าค่า cost function ที่ได้เป็น 1519000

- ก็นำเอาค่าความเคลื่อนที่ได้ ไปปรับ Model เข้าหาผลลัพธ์ที่ถูกต้อง
- จากสมการความชันที่ทำอนุพันธ์กับสมการ Cost Function ซึ่งจะได้ดังนี้

- จะเห็นว่าค่าความชันของ m จะมีค่าเท่ากับ -17720 ซึ่งเป็นตัวเลขติดลบแสดงว่าเราต้องบวกค่า m เพิ่มเพื่อให้ความชันใกล้ศูนย์
- ค่าความชันของ b จะมีค่าเท่ากับ -546 ซึ่งเป็นตัวเลขติดลบแสดงว่าเราต้องบวกค่า b เพิ่มขึ้นเพื่อให้ความชันใกล้ศูนย์
- จากค่า m และ b ใน model เดิมคือ 210 และ 2600 เราจะทำการปรับดังนี้ครับ
- m = m – ((-17720) * LearningRate) = 210-((-17720) * 0.001) = 227.72
- b=b-((-546)*LearningRate) = -2600-((-546)*0.001) = -2,599.454
- จากสมการ เราจะเอาค่าที่ได้จากการคำนวณความชันที่ได้มาปรับ model หรือก็คือการปรับค่า m และ b ใหม่ จากสมการจะเห็นว่าจะมีตัวแปรหนึ่งที่ชื่อว่า LearningRate มาคูณก่อนแล้วคอยไปปรับค่า ซึ่ง LearningRate จะเป็นค่าคงที่ ในที่นี้ผมให้มีค่าเป็น 0.001 ดังนั้นค่าใหม่ที่ได้ก็จะเป็น m = 211.772 และ b = -2,599.9454

- หลังจากนั้นจะทำการ Train ไปเรื่อยๆและปรับค่า Model ไปเรื่อยๆ(คือการปรับค่า m และ b)
- จนใกล้เคียงข้อมูลจริงมากที่สุด
สุดท้ายนี้หวังว่าโพสน์นี้จะมีประโยชน์สำหรับแนวทางในการเริ่มต้นศึกษา Machine learning ครับและหากใครอยากทดลองเขียนโปรแกรม
Linear เองสามารถดู code ได้ที่ https://github.com/CakeNuthep/Linear-Regression
ไม่มีความคิดเห็น:
แสดงความคิดเห็น